From Node.js Design Patterns by Mario Casciaro and Luciano Mammino
Node.js is one of the most popular languages for web servers, even though JavaScript is single-threaded. This might seem contradictory at first---don’t web servers need to handle simultaneous connections?
The answer is something built into the language called the reactor pattern. The reactor pattern allows Node.js to not only “multithread” but to do so in a resource-efficient way that makes it perfect for microservices.
This post is based on and uses diagrams from Node.js Design Patterns by Mario Casciaro and Luciano Mammino. It’s an excellent book I would recommend to anyone interested in Node.
A brief history of web servers
To understand Node.js, let’s look at what web servers have to do.
Imagine you are running a simple REST API for sandwiches. The user can POST, GET, PATCH, or DELETE sandwiches from a server-side database through an API.
Here’s what happens when a user sends a GET request:
- The server accepts the incoming request
- It establishes a TCP connection
- It reads request content from the socket
- It retrieves the requested sandwich data from the database
- It writes the response to the client
- It closes the connection
These steps are not true of all server connections---you might use keep-aliveheaders to reuse the previous TCP connection, or you might be using WebSockets, or you might not be using REST at all. But to explain a GET request to a RESTful JSON API, this model will suffice.
One major problem facing web servers is the time it takes to read the database. Slow read times can be caused by a few things: database size, instance distribution, etc.
Simultaneous connections compound the database read-time problem. Most websites are used by more than one person at a time. Your web server cannot just hang around waiting for the response from the database before responding to the next user! Imagine waiting in line to use Google.
Servers have handled this problem in several different ways over the years. The first web server, httpd, would spin up a whole new process for each connection to it. This avoided multithreaded code, which is hard to write correctly, and weird race conditions. However, httpd consumed a lot of memory, and it hasn’t been updated since 1997.
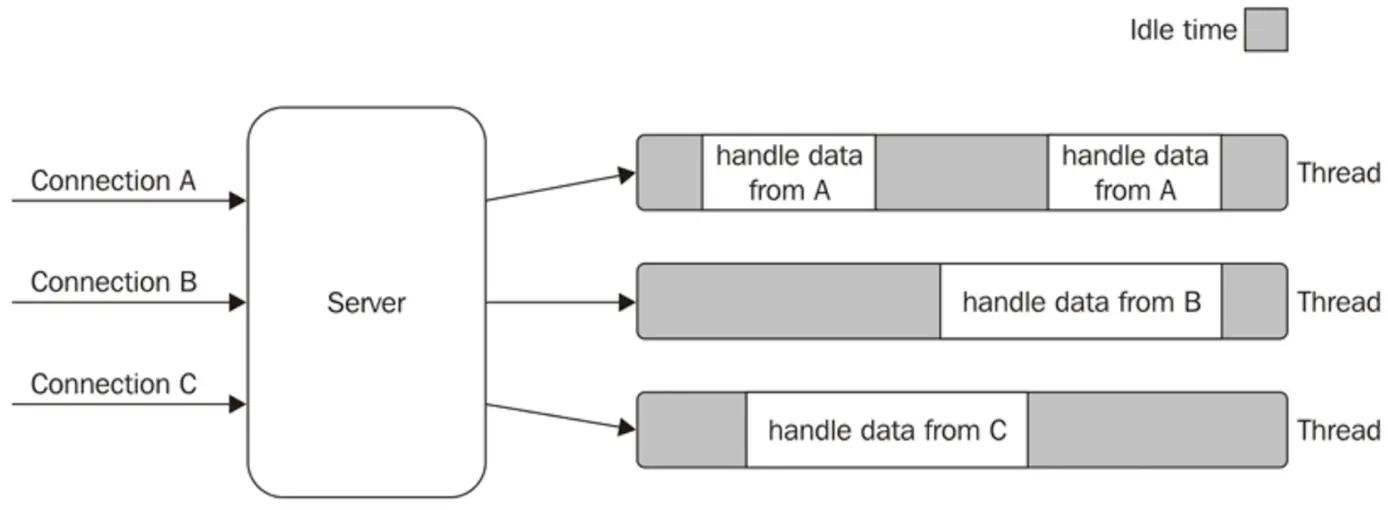
So people moved on. These days, many server frameworks use a thread pool. Many requests come into a server, which assigns one thread to each request. Then, if the thread is waiting on a slow database request, it’s no big deal to other users. Their fast request can complete on some other thread.
This is a good, flexible approach to scaling. Just add more threads! The downside is it can also take up a lot of memory. Consider this diagram of a server that uses one thread per connection.
The Node.js approach
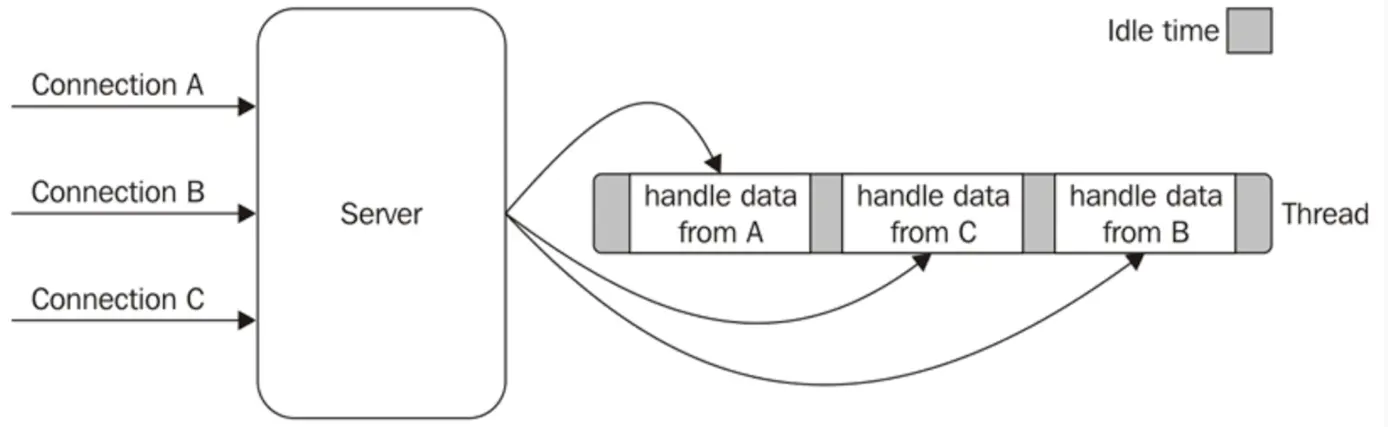
Node.js is written in JavaScript. It is single-threaded, meaning it can only do one thing at a time.
At first glance, this seems incompatible with serving multiple connections simultaneously. However, Node.js and JavaScript fake multithreading using the event loop to hop between multiple tasks.
To return to your sandwich API, let’s say the server uses this Express code to respond to GET requests:
router.get('/sandwiches/:id', (reg, res) => {
const sandwichId = req.params.id;
database.findOneById(sandwichId).then(sandwich => {
console.log('lunch time');
res.json(sandwich);
});
console.log('searching for sandwich');
});When this code runs, it will execute these steps:
- Assign
sandwichId - Dispatch an asynchronous operation,
findOneById - Log
"searching for sandwich" - Wait for the database to return the requested sandwich
- Run the callback provided on line 3 when the database returns some data
- Log
"lunch time" - Send the sandwich data to the client
- Wait for a new request
Node.js can fake multithreading and multiple clients because, during steps 4 and 8, it can serve other requests. If another request comes in during step 2, Node can respond to it during step 4, then go back and continue at step 5 to finish responding to the original request.
Think of Node as a chef running around the kitchen. The chef can set a pot of water to boil, then jump over and chop some onions, then put dry spaghetti in the water, then chop some carrots. The chef can only do one thing at a time, but they can multitask.
Node.js fakes multithreading by multitasking. It spreads out tasks, not across threads or processes, but time.
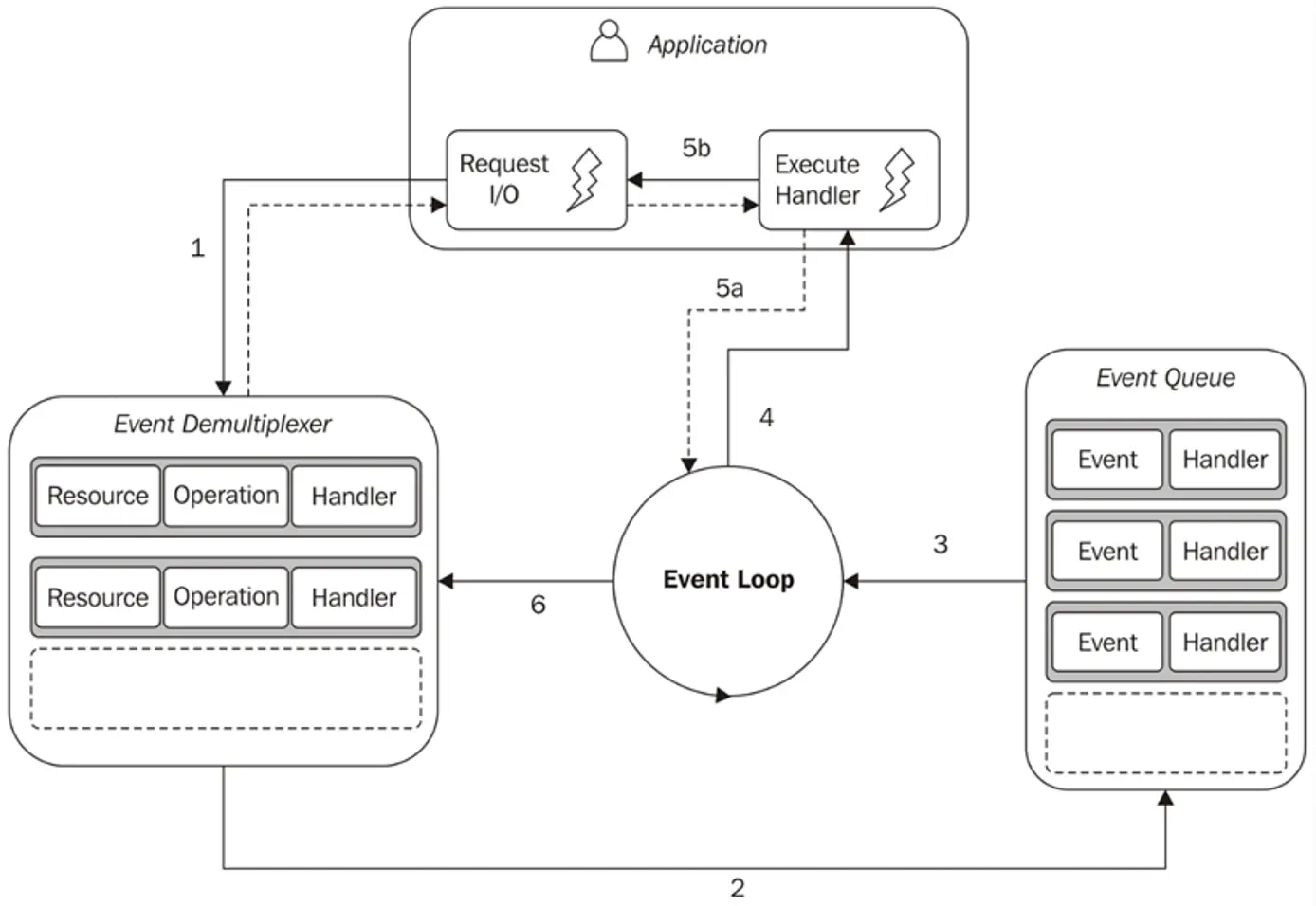
The way Node hops around between tasks is explained by the reactor pattern. Node is structured like a reactor, where the flow of control swirls around the event loop, processing tasks as they come in.

When you run a JavaScript file in Node, it starts at the top square, “Execute Handler.” It will synchronously run the code provided until that code is finished. If an asynchronous operation is triggered while running the code, that operation is sent to the box on the left, the event demultiplexer.
The synchronous event demultiplexer is a complicated name for a part of Node that just means “in-progress async operations.” When your JS code triggers a request to the file system or network, the synchronous event demultiplexer is where the request lives in Node while it’s in progress. If Node is not actively running JS code, Node will “block” or wait here until one of the async operations finishes.
When an async operation in the demultiplexer finishes, Node moves it to the event queue. When Node is finished running the current bit of JavaScript, it gets the next finished async operation from the queue and runs the callback associated with it.
Let’s return to your sandwich API one more time:
router.get('/sandwiches/:id', (reg, res) => {
const sandwichId = req.params.id;
database.findOneById(sandwichId).then(sandwich => {
console.log('lunch time');
res.json(sandwich);
});
console.log('searching for sandwich');
});This can now be explained using the reactor pattern. First, the application synchronously runs the code in the .get() callback. It adds an async event to the event demultiplexer (the database request). Then, Node won’t do anything because it has no more JS to run.
When the database request finishes, the event demultiplexer adds it to the event queue. Node grabs it from the queue and runs the callback associated with the finished event. In this case, it’s the anonymous function on lines 3 - 6. When the callback is finished, Node waits for another request.
Node runs on a single piece of JavaScript until it’s finished. Any async operations are added to the demultiplexer. When the operations finish, they’re added to the event queue. When Node is done running the current piece of JS, it grabs the next item from the queue. If that item causes another async operation, that operation is added to the demultiplexer, and so on.
How does Node.js “multithreading” scale?
It’s understandable to question how Node.js scales once you understand it only runs on one thread. How can this serve when you have many users?
First, even if JavaScript is not incredibly efficient, JavaScript interpreters are. Google has put significant money and development time into V8, the JS engine that powers Node. Apple has done the same with JavaScriptCore, the interpreter that runs in Safari (and all web content on iOS). ARM chips ship with special hardware capabilities to handle JS math.
Second, scaling servers is actually a whole other problem that exists outside of your choice of server language. If you need industrial scale for your web app, you’ll have to worry about load balancing and proxies and CDNs and lots of other things before the user even touches your server API code.
Works Cited
- Node.js Design Patterns by Mario Casciaro and Luciano Mammino (3rd Ed.)
- Understanding Reactor Pattern for Highly Scalable I/O Bound Web Server by Tian Pan